在進行資料專案時,模型是基於數學設計的,有些資料型態不適合模型存取,為了提高數據的可用性和模型的處理,本文將以案例說明如何進行資料型態轉換,內容包含:
資料的類型可分為「字串」、「數字」、「布林值」三種。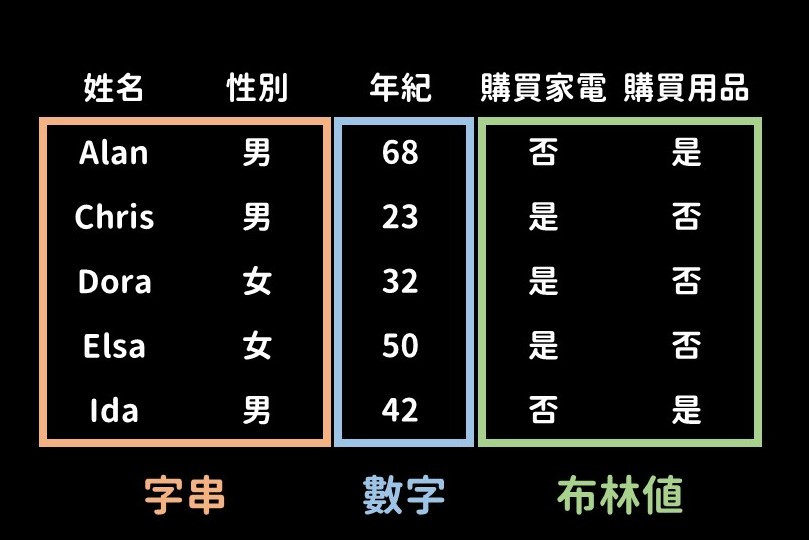
在資料的三種型態中,模型無法辨識字串,必須先轉換成數值才能使用,有以下兩種方法:
1. 標籤編碼法(Label Encoding)
使用 sklearn 中的函數 LabelEncoder 操作,自動將字串轉換成對應的數字,會改變原先的數據,適用於「有序類別字串」,轉換後以數值大小維持資料順序。
(1) 舉例:將青年、壯年、老年的資料,分別轉換成數值型態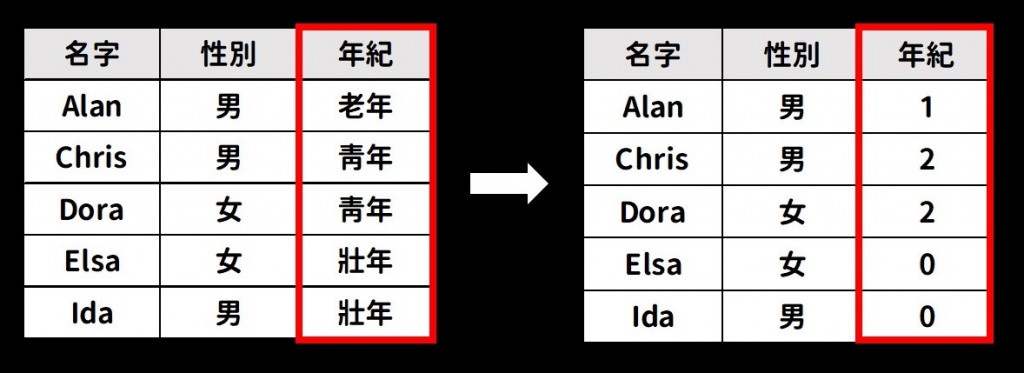
(2) 程式碼
import pandas as pd
data = {'name':['Alan','Chris','Dora','Elas','Ida'],
'gender':['M','M','F','F','M'],
'age':['老年','青年','青年','壯年','壯年']}
df = pd.DataFrame(data)
# 從sklearn中導入Label Encoding
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
# 新增age_labelencoded欄位呈現轉換後的結果
df['age_labelencoded'] = label_encoder.fit_transform(df['age'])
# 直接覆蓋age欄位呈現轉換後的結果
df['age'] = label_encoder.fit_transform(df['age'])
print(df)
(3) 輸出結果:
2. 獨熱編碼法(One-Hot Encoding)
使用 Pandas 提供的 get_dummies(data, columns, dtype = bool 或 int) 語法,將字串轉為數值,並使用二進制向量,用 0 或 1 表示,不會改變原先的數據,適用於「無序類別字串」。
(1) 舉例:將 gender 的性別以 0 或 1 的數值表示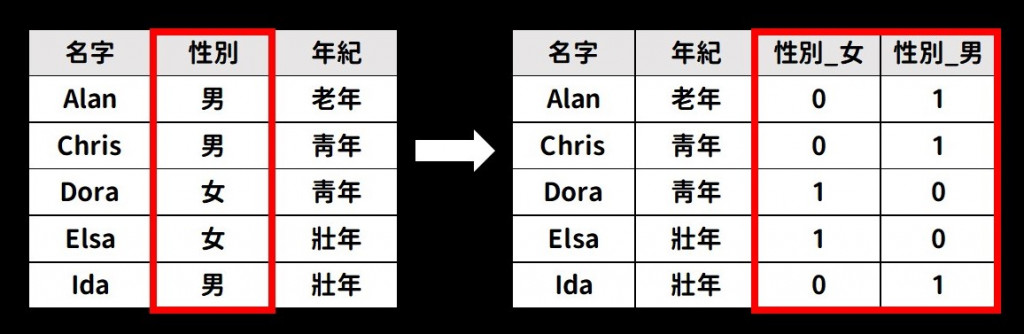
(2) 程式碼:
import pandas as pd
data = {'name':['Alan','Chris','Dora','Elas','Ida'],
'gender':['M','M','F','F','M'],
'age':['老年','青年','青年','壯年','壯年']}
df = pd.DataFrame(data)
# 不改變df,存在變數onehotencoded
onehotencoded = pd.get_dummies(df, columns=['gender'],dtype=int)
print(onehotencoded)
(3) 輸出結果:
在資料型態不一致時,採取適當的資料型態轉換方法,可以協助增加特徵或提高模型的性能!如果有任何不理解、錯誤或其他方法想分享的話,歡迎留言給我!喜歡的話,也歡迎按讚訂閱唷!
我是 Eva,一位正在努力跨進資料科學領域的女子!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】


 iThome鐵人賽
iThome鐵人賽